
We marketers create campaigns based on experience, intuition or past performance, but we know it's hard to predict how the market will respond, so we use tools at our disposal to help guide our decision-making process. Things like focus groups or surveys are expensive and may take a lot of time to implement. Or we can run an A/B test on digital, which requires large traffic to be statistically significant.
In the age of AI, a few methodologies in research have emerged that can help accelerate the decision-making process. At least some of these methods will provide guidance and inspiration if a new creative idea is on the right track while saving you a bunch of time and money. At best, you will have a testing engine that will help you how your market will react given a set of conditions.
A quick intro to synthetic participants
The principle is simple: you use a large language model to simulate a human response (or a collective of human responses) to approximate how real demographic groups might respond, enabling rapid, low-cost hypothesis testing before (or alongside) traditional research.
Something important to note is that this differs from just "asking ChatGPT for feedback". The core idea is that you provide the AI with one or more persona schemas detailing nuanced demographic, psychographic, attitudinal, and other information and then ask it a series of questions to either validate your content, ask for guidance, scrutinise ideas, etc. Exactly like you would do in a focus group, survey, etc.
The surprising fact is that LLMs have an amazing ability to mimic human behaviours and biases.
Research conducted by an IT team at UNSW, Australia found that when ChatGPT was prompted to act as a human (e.g., “You are a senior IT manager…”) it reproduced typical human decision biases such as over‑confidence, anchoring, and confirmation bias. In contrast, an “AI” prompt produced more analytical, consistent decisions with fewer biases. Source: The Role of Roles: When are LLMs Behavioural in Information Systems Decision-Making
In this series, I will deep dive on the concept of the synthetic participants and a few levels of techniques that will allow you to incorporate them into your own workflow. I will share examples you can apply to your own work, which will hopefully inspire you to find new uses in your own practice.
Before we start: the persona schema is everything
A persona schema is simply a structured template that defines who each synthetic participant is. It's the set of attributes you assign to an AI persona so it can respond consistently "in character." Think of it like a character sheet in a role-playing game but for research.
If you just say "respond as a young woman", the LLM fills in everything else arbitrarily. A schema forces you to be explicit and systematic about which variables matter for your research, making results reproducible and comparable.
A typical persona schema includes layers of identity:
Demographics
- Age, gender, ethnicity, nationality
- Location (urban/rural, region, country)
- Education level, occupation, income bracket
- Family structure (married, children, etc.)
Psychographics
- Values and beliefs
- Political orientation
- Risk tolerance
- Openness to change
Context
- Life circumstances relevant to your study
- Recent experiences that shape their perspective
- Access to resources, technology, healthcare, etc.
Behavioural traits
- Communication style (formal/informal, verbose/terse)
- Decision-making approach (analytical, emotional, social)
- Information sources they trust
Be sure that you have at least a good idea of your ICP so that you can use this type of workflow in your own creative journey.
Ok, so let's start playing with the different levels of synthetic predictions.
Level 1 : Your first synthetic test against one persona
The structure of a synthetic test is always the same: persona + content + question. You describe who the participant is, show them what you want tested, and ask them to react:
[Persona block] Who they are, drawn from your schema
[Content block] The actual asset you're testing (email, ad, landing page, subject line)
[Question block] What you want to know
Walkthrough - Example
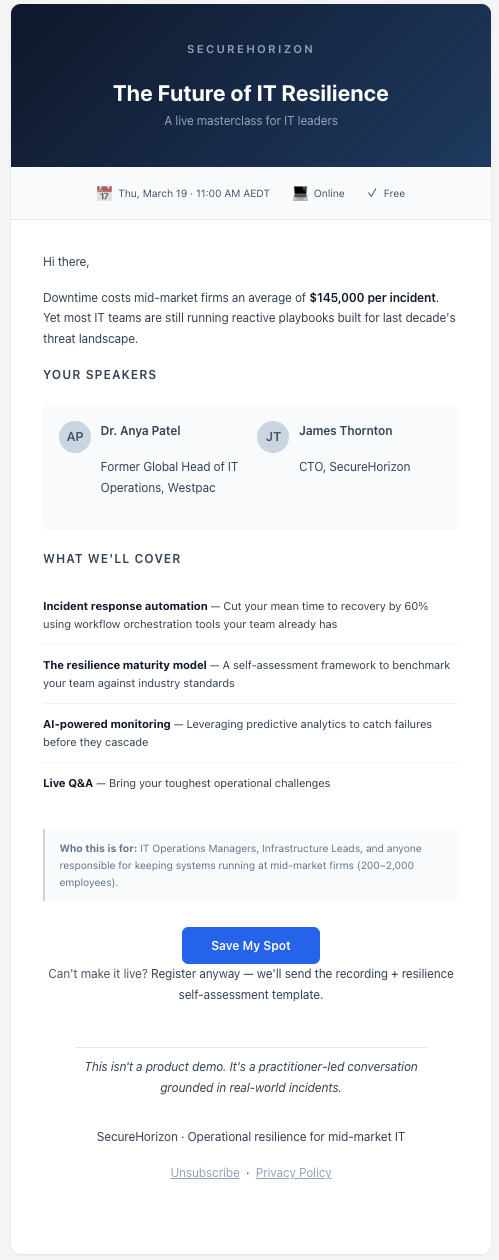
Say you have a webinar invitation email and you want to know whether it would land with a mid-level IT operations manager. You'd prompt your LLM like this:
You are Rachel, a 38-year-old IT Operations Manager at a mid-sized financial services firm in Melbourne. You manage a team of 6 and report to the CTO. You're pragmatic, time-poor, and skeptical of vendor marketing. You attend 1-2 webinars per quarter but only when the topic directly addresses a current problem. You prefer plain-spoken content over buzzwords. You typically scan emails on your phone during your morning commute.
You have just received the following email in your work inbox:
[paste your email here]
As Rachel, answer the following:What is your first impression of the subject line? Would you open this email?If you opened it, what part of the body would catch your attention first?Would you register for this webinar? Why or why not?What would need to change for you to say yes (if you said no) or feel more confident (if you said yes)?
You can do this right now in any LLM chat interface.
I ran the prompt on a fictional webinar invitation. You can see the output below, and if you'd like to examine it closer you can download it on this github repository.

Tips for your first run
- Be specific in the persona, open-ended in the questions. The more detail you give the persona, the more grounded the response. But keep your questions broad enough that the persona can surprise you.
- Paste real content. Don't describe your email — paste the actual copy. The model needs to react to your words, not your summary of them.
- Watch for the "too helpful" trap. If your synthetic participant sounds like a marketing consultant giving you feedback, your prompt is probably too vague. Real participants don't offer strategy — they tell you whether they'd act or not.
- What this method is good at:
- directional signal, catching blind spots, speed, testing messaging angles
- Not good at: predicting exact conversion rates, replacing real user research, cultural nuance
- The key mindset: synthetic respondents are a draft check, not a final answer
Conclusion
One persona gives you one perspective. Rachel's feedback is genuinely useful. But it's still one person's reaction. Would a junior sysadmin notice the same things? Would a CISO care about the MTTR bullet at all? Would a non-technical procurement lead even open it?
The risk of stopping at one persona is that you optimise for Rachel and accidentally alienate other personas in your buyer groups. The next step in our journey is to build a panel.
